Tesseract is an optical character recognition engine for various operating systems. It is free software, released under the Apache License, Version 2.0, and development has been sponsored by Google since 2006. Tesseract is considered one of the most accurate open source OCR engines currently available Wikipedia
Image processing is widely used in helping to resolve the problems. OCR is one of image processing technology. OCR (Optical Character Recognition) is a system that is able to recognize handwriting that is on an image. OCR is very helpful in the process of editing and production of a document that comes from the writing of the hardcopy and captured into an image. The information contained in these writings will certainly be used and processed by some people to see it. Image capturing process is done using multiple devices such as digital cameras, mobile phones, webcams, and others.
This is snipcode to runing Tesseract OCR
/**
* Created by KrisnaPutra on 1/17/2016.
*/
public class ImageProcessingOCR {
private TessBaseAPI mTess;
public ImageProcessingOCR( String p_packageName) {
// TODO Auto-generated constructor stub
mTess = new TessBaseAPI();
String language = "eng";
mTess.init(p_packageName, language);
}
public String getOCRResult(Bitmap bitmap) {
mTess.setImage(bitmap);
String result = mTess.getUTF8Text();
Log.d("+++++++++++Result ",result);
return result;
}
public void onDestroy() {
if (mTess != null)
mTess.end();
}
}
This is the result
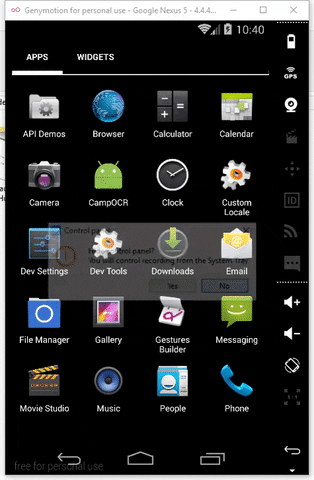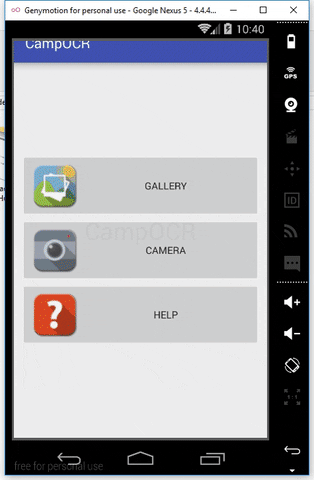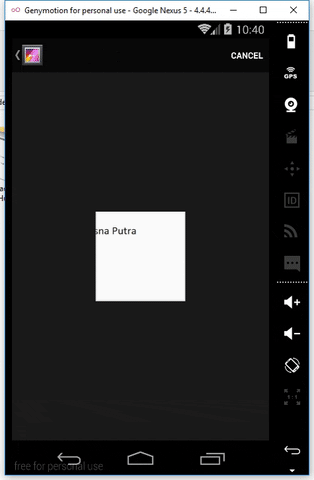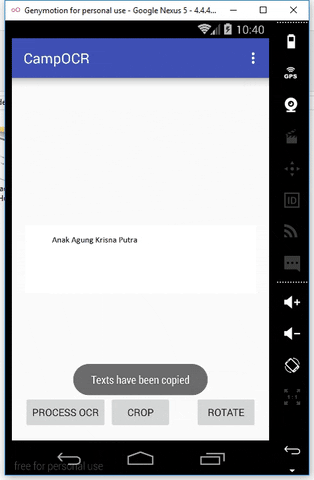
Feature CampOCR
- Image Processing OCR
- Get Image from Camera and From Gallery
- Crop Image
- Rotate Image
- Change Constrast and Brightness
If you enjoyed this article, please consider sharing it!




